
推荐:看到如此多的 MVP+Dagger2+Retrofit+Rxjava 项目, 轻松拿 star, 心动了吗? 看到身边的朋友都已早早在项目中使用这些技术, 而你还不会, 失落吗?
MVPArms 是一个 MVP+Dagger2+Retrofit+Rxjava 可配置化快速集成框架(目前 Dagger 应用最复杂可配置化极强的集成框架), 自带上万字 文档 以及 一键生成 MVP 和 Dagger2 文件等功能, 成熟稳定且已有上千个商业项目接入, 累计 5k+ star(全球第一 MVP 框架), 现在你只用专注于逻辑, 其他都交给 MVPArms, 快来构建自己的 MVP+Dagger2+Retrofit+Rxjava 项目吧!|
:———-:|
前言
Retrofit无疑是当下最火的网络请求库,与同门师兄Okhttp配合使用,简直是每个项目的标配,因为Okhttp自带缓存,所以很多人并不关心其他缓存库,但是使用过Okhttp缓存的小伙伴,肯定知道Okhttp的缓存必须配合Header使用,比较麻烦,也不够灵活,所以现在为大家推荐一款专门为Retrifit打造的缓存库RxCache
项目地址: RxCache Demo地址: RxCacheSample
简介
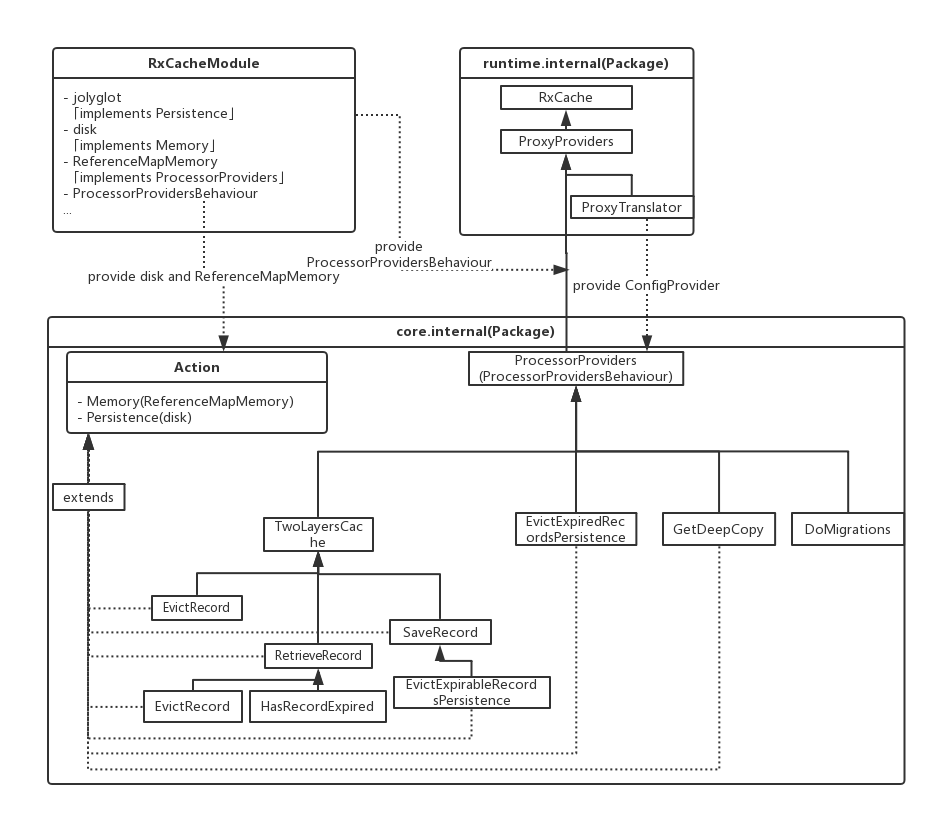
RxCache使用注解来为Retrofit配置缓存信息,内部使用动态代理和Dagger来实现,这个库的资料相对较少,官方教程又是全英文的,这无疑给开发者增加了使用难度,其实我英文也不好,但是源码是通用的啊,所以我为大家从源码的角度来讲解此库,此库源码的难点其实都在Dagger注入上,我先为大家讲解用法,后面会再写篇文章讲解源码,在学习Dagger的朋友除了建议看看我的MVPArms外,还可以看看这个RxCache的源码,能学到很多东西,先给张RxCache的架构图,让大家尝尝鲜,请期待我后面的源码分析😏
使用
1.定义接口,和Retrofit类似,接口中每个方法和Retrofit接口中的方法一一对应,每个方法的参数中必须传入对应Retrofit接口方法的返回值(返回值必须为Observable,否则报错),另外几个参数DynamicKey,DynamicKeyGroup和EvictProvider不是必须的,但是如果要传入,每个都只能传入一个对象,否则报错,这几个参数的意义是初学者最困惑的,后面会分析
/**
* 此为RxCache官方Demo
*/
public interface CacheProviders {
@LifeCache(duration = 2, timeUnit = TimeUnit.MINUTES)
Observable<Reply<List<Repo>>> getRepos(Observable<List<Repo>> oRepos, DynamicKey userName, EvictDynamicKey evictDynamicKey);
@LifeCache(duration = 2, timeUnit = TimeUnit.MINUTES)
Observable<Reply<List<User>>> getUsers(Observable<List<User>> oUsers, DynamicKey idLastUserQueried, EvictProvider evictProvider);
Observable<Reply<User>> getCurrentUser(Observable<User> oUser, EvictProvider evictProvider);
}
2.将接口实例化,和Retrofit构建方式类似,将接口通过using方法传入,返回一个接口的动态代理对象,调用此对象的方法传入对应参数就可以实现缓存了,通过注解和传入不同的参数可以实现一些自定义的配置, so easy~
CacheProviders cacheProviders = new RxCache.Builder()
.persistence(cacheDir, new GsonSpeaker())
.using(CacheProviders.class);
详解
其实RxCache的使用比较简单,上面的两步就可以轻松的实现缓存,此库的的特色主要集中在对缓存的自定义配置,所以我来主要讲讲那些参数和注解是怎么回事?
参数
Observable
此Observable的意义为需要将你想缓存的Retrofit接口作为参数传入(返回值必须为Observable),RxCache会在没有缓存,或者缓存已经过期,或者EvictProvider为true时,通过这个Retrofit接口重新请求最新的数据,并且将服务器返回的结果包装成Reply返回,返回之前会向内存缓存和磁盘缓存中各保存一份
值得一提的是,如果需要知道返回的结果是来自哪里(本地,内存还是网络),是否加密,则可以使用Observable<Reply<List<Repo>>>作为方法的返回值,这样RxCache则会使用Reply包装结果,如果没这个需求则直接在范型中声明结果的数据类型Observable<List<Repo>>
例外
如果构建RxCache的时候将useExpiredDataIfLoaderNotAvailable设置成true,会在数据为空或者发生错误时,忽视EvictProvider为true或者缓存过期的情况,继续使用缓存(前提是之前请求过有缓存)
DynamicKey & DynamicKeyGroup
有很多开发者最困惑的就是这两个参数的意义,两个一起传以及不传会有影响吗?说到这里就要提下,RxCache是怎么存储缓存的,RxCache并不是通过使用URL充当标识符来储存和获取缓存的
那是什么呢?
没错RxCache就是通过这两个对象加上上面CacheProviders接口中声明的方法名,组合起来一个标识符,通过这个标识符来存储和获取缓存
标识符规则为:
方法名 + $d$d$d$" + dynamicKey.dynamicKey + "$g$g$g$" + DynamicKeyGroup.group
dynamicKey或DynamicKeyGroup为空时则返回空字符串,即什么都不传的标识符为:
"方法名$d$d$d$$g$g$g$"
什么意思呢?
比如RxCache,的内存缓存使用的是Map,它就用这个标识符作为Key,put和get数据(本地缓存则是将这个标识符作为文件名,使用流写入或读取这个文件,来储存或获取缓存),如果储存和获取的标识符不一致那就取不到想取的缓存
和我们有什么关系呢?
举个例子,我们一个接口具有分页功能,我们使用RxCache给他设置了3分钟的缓存,如果这两个对象都不传入参数中,它会默认使用这个接口的方法名去存储和获取缓存,意思是我们之前使用这个接口获取到了第一页的数据,三分钟以内多次调用这个接口,请求其他分页的数据,它返回的缓存还是第一页的数据,直到缓存过期,所以我们现在想具备分页功能,必须传入DynamicKey,DynamicKey内部存储有一个key,我们在构建的时候传入页数,RxCache将会根据不同的页数分别保存一份缓存,它内部做的事就是将方法名+DynamicKey变成一个String类型的标识符去获取和存储缓存
DynamicKey和DynamicKeyGroup有什么关系呢
DynamicKey存储有一个Key,DynamicKey的应用场景: 请求同一个接口,需要参照一个变量的不同返回不同的数据,比如分页,构造时传入页数就可以了
DynamicKeyGroup存储有两个key,DynamicKeyGroup是在DynamicKey基础上的加强版,应用场景:请求同一个接口不仅需要分页,每页又需要根据不同的登录人返回不同的数据,这时候构造DynamicKeyGroup时,在构造函数中第一个参数传页数,第二个参数传用户标识符就可以了
理论上DynamicKey和DynamicKeyGroup根据不同的需求只用传入其中一个即可,但是也可以两个参数都传,以上面的需求为例,两个参数都传的话,它会先取DynamicKey的Key(页数)然后再取DynamicKeyGroup的第二个Key(用户标识符),加上接口名组成标识符,来获取和存储数据,这样就会忽略DynamicKeyGroup的第一个Key(页数)
EvictProvider & EvictDynamicKey & EvictDynamicKeyGroup
这三个对象内部都保存有一个boolean类型的字段,其意思为是否驱逐(使用或删除)缓存,RxCache在取到未过期的缓存时,会根据这个boolean字段,考虑是否使用这个缓存,如果为true,就会重新通过Retrofit获取新的数据,如果为false就会使用这个缓存
这三个对象有什么关系呢?
这三个对象是相互继承关系,继承关系为EvictProvider < EvictDynamicKey < EvictDynamicKeyGroup,这三个对象你只能传其中的一个,多传一个都会报错,按理说你不管传那个对象都一样,因为里面都保存有一个boolean字段,根据这个字段判断是否使用缓存
不同在哪呢?
如果有未过期的缓存,并且里面的boolean为false时,你传这三个中的哪一个都是一样的,但是在boolean为true时,这时就有区别了,RxCache会在Retrofit请求到新数据后,在boolean为true时删除对应的缓存
删除规则是什么呢?
还是以请求一个接口,该接口的数据会根据不同的分页返回不同的数据,并且同一个分页还要根据不同用户显示不同的数据为例
三个都不传,RxCache会自己new EvictProvider(false);,这样默认为false就不会删除任何缓存
EvictDynamicKeyGroup 只会删除对应分页下,对应用户的缓存
EvictDynamicKey 会删除那个分页下的所有缓存,比如你请求的是第一页下user1的数据,它不仅会删除user1的数据还会删除当前分页下其他user2,user3…的数据
EvictProvider 会删除当前接口下的所有缓存,比如你请求的是第一页的数据,它不仅会删除第一页的数据,还会把这个接口下其他分页的数据全删除
所以你可以根据自己的逻辑选择传那个对象,如果请求的这个接口没有分页功能,这时你不想使用缓存,按理说你应该传EvictProvider,并且在构造时传入true,但是你如果传EvictDynamicKey和EvictDynamicKeyGroup达到的效果也是一样
注解
@LifeCache
@LifeCache顾名思义,则是用来定义缓存的生命周期,当Retrofit获取到最新的数据时,会将数据及数据的配置信息封装成Record,在本地和内存中各保存一份,Record中则保存了@LifeCache的值(毫秒)和当前数据请求成功的时间(毫秒)timeAtWhichWasPersisted
以后每次取缓存时,都会判断timeAtWhichWasPersisted+@LifeCache的值是否小于当前时间(毫秒),小于则过期,则会立即清理当前缓存,并使用Retrofit重新请求最新的数据,如果EvictProvider为true不管缓存是否过期都不会使用缓存
@EncryptKey & @Encrypt
这两个注解的作用都是用来给缓存加密,区别在于作用域不一样
@EncryptKey是作用在接口上
@EncryptKey("123")
public interface CacheProviders {
}
而@Encrypt是作用在方法上
@EncryptKey("123")
public interface CacheProviders {
@Encrypt
Observable<Reply<User>> getCurrentUser(Observable<User> oUser, EvictProvider evictProvider);
}
}
如果需要给某个接口的缓存做加密的操作,则在对应的方法上加上@Encrypt,在存储和获取缓存时,RxCache就会使用@EncryptKey的值作为Key给缓存数据进行加解密,因此每个Interface中的所有的方法都只能使用相同的Key
值得注意的时,RxCache只会给本地缓存进行加密操作,并不会给内存缓存进行加密,给本地数据加密使用的是Java自带的CipherInputStream,解密使用的是CipherOutputStream
@Expirable
还记得我们在构建RxCache时,有一个setMaxMBPersistenceCache方法,这个可以设置,本地缓存的最大容量,单位为MB,如果没设置则默认为100MB
这个最大容量和@Expirable又有什么关系呢?
当然有!还记得我之前说过在每次Retrofit重新获取最新数据时,返回数据前会将最新数据在内存缓存和本地缓存中各存一份
存储完毕后,会检查现在的本地缓存大小,如果现在本地缓存中存储的所有缓存大小加起来大于或者等于setMaxMBPersistenceCache中设置的大小(默认为100MB)的百分之95,RxCache就会做一些操作,将总的缓存大小控制在百分之70以下
做的什么操作?
很简单,RxCache会遍历,构建RxCache时传入的cacheDirectory中的所有缓存数据,一个个删除直到总大小小于百分70,遍历的顺序不能保证,所以搞不好对你特别重要的缓存就被删除了,这时@Expirable就派上用场了,在方法上使用它并且给它设置为false(如果没使用这个注解,则默认为true),就可以保证这个接口的缓存数据,在每次需要清理时都幸免于难
@Expirable(false)
Observable<Reply<User>> getCurrentUser(Observable<User> oUser, EvictProvider evictProvider);
值得注意的是: 构建RxCache时persistence方法传入的cacheDirectory,是用来存放RxCache本地缓存的文件夹,这个文件夹里最好不要有除RxCache之外的任何数据,这样会在每次需要遍历清理缓存时,节省不必要的开销,因为RxCache并没检查文件名,不管是不是自己的缓存,他都会去遍历获取
@SchemeMigration & @Migration
这两个注解是用来数据迁移的,用法:
@SchemeMigration({
@Migration(version = 1, evictClasses = {Mock.class}),
@Migration(version = 2, evictClasses = {Mock2.class})
})
interface Providers {}
什么叫数据迁移呢?
简单的说就是在最新的版本中某个接口返回值类型内部发生了改变,从而获取数据的方式发生了改变,但是存储在本地的数据,是未改变的版本,这样在反序列化时就可能发生错误,为了规避这个风险,作者就加入了数据迁移的功能
有什么应用场景呢?
可能上面的话,不是很好理解,举个非常简单的例子:
public class Mock{
private int id;
}
Mock里面有一个字段id,现在是一个整型int,能满足我们现在的需求,但是随着产品的迭代,发现int不够用了
public class Mock{
private long id;
}
为了满足现在的需求,我们使用long代替int,由于缓存中的Mock还是之前未改变的版本,并且未过期,在使用本地缓存时会将数据反序列化,将int变为long,就会出现问题
数据迁移是怎么解决上面的问题呢?
其实非常简单,就是使用注解声明,之前有缓存并且内部修改过的class,RxCache会把含有这些class的缓存全部清除掉
RxCache是怎么操作的呢?
值得一提的是,在每次创建接口的动态代理时,也就是在每次调用RxCache.using(CacheProviders.class)时,会执行两个操作,清理含有@Migration中声明的evictClasses的缓存,以及遍历本地缓存文件夹清理所有已经过期的缓存
每次清理完需要数据迁移的缓存时,会将version值最大的@Migration的version值保存到本地
@SchemeMigration({
@Migration(version = 1, evictClasses = {Mock.class}),
@Migration(version = 3, evictClasses = {Mock3.class}),
@Migration(version = 2, evictClasses = {Mock2.class})
})
interface Providers {}
如上面的声明方式,它会将3保存到本地,每次调用using(),开始数据迁移时会将上次保存的version值从本地取出来,会在@SchemeMigration中查找大于这个version值的@Migration,取出里面evictClasses,去重后,遍历所有本地缓存,只要缓存数据中含有你声明的class,就将这个缓存清除
比如evictClasses中声明了Mock.class,会把以Observable< List< Mock »,Observable< Map< String,Mock > >,Observable < Mock[] >或者Observable< Mock >作为返回值的接口缓存全部清理掉,然后在将最大version值记录到本地
所以每次有需要数据迁移的类时,必须在@SchemeMigration中添加新的@Migration,并且注解中version的值必须+1,这样才会达到数据迁移的效果
@SchemeMigration({
@Migration(version = 1, evictClasses = {Mock.class}),
@Migration(version = 3, evictClasses = {Mock3.class}),
@Migration(version = 2, evictClasses = {Mock2.class}),
@Migration(version = 4, evictClasses = {Mock2.class})
})
interface Providers {}
如在上面的基础上,Mock2内部又发生改变,又需要数据迁移,就要新添加个@Migration,version = 4(3+1),这时在调用using()时只会将version = 4的@Migration中evictClasses声明的class进行数据迁移(即清理含有这个class的缓存数据)
@Actionable
这个注解在官方介绍中说明了会使用注解处理器给使用了这个注解的Interface,自动生成一个相同类名以Actionable结尾的类文件,使用这个类的APi方便更好的执行写操作,没使用过,不做过多介绍
总结
到这里RxCache的介绍就告一段落了,相信看完这篇文章后,基本使用肯定是没问题的
但是在使用中发现了一个问题,如果使用BaseResponse< T >,包裹数据的时候会出现错误,如issue$41和issue#73
分析问题
上面说了RxCache会将Retrofit返回的数据封装到Record对象里,Record会判断这个数据是那种类型,会先判断这个数据是否是Collection(List的父类),数组还是Map,如果都不是他会默认这个数据就是普通的对象
Record里有三个字段分别储存这个数据的,容器类名,容器里值的类名,和Map的Key类名,意思为如果数据类型为List< String >,容器类名为List,值类名为String,Key类名为空,如果数据类型为Map< String,Integer >,容器类名为Map,值类名为Integer,key类名为String
这三个字段的作用就是,在取本地缓存时可以使用Gson根据字段类型恢复真实数据的类型,问题就在这,因为使用的是BaseResponse< T >包裹数据,在上面的判断里,他排除了这个数据是List,数组或Map后它只会认定这个数据是普通的对象,这时他只会把三个字段里中值类名保存为BaseResponse其他则为空,范型的类型它并没通过字段记录,所以它在取的时候自然不会正确返回T的类型
解决问题
知道问题所在后,我们现在就来解决问题,解决这个问题现在有两个方向,一个是内部解决,一个是外部解决,外部解决的方式就可以通过上面issue#73所提到的方式
所谓内部解决就要改这个框架的内部代码了,问题就出在Record在数据为普通对象的时候,他不会使用字段保存范型的类型名,所以在取本地缓存的时候就无法正确恢复数据类型
解决的思路就是我们必须对数据为普通对象的时候做特殊处理,最简单的方式就是如果数据为对象时我们再判断instanceof BaseResponse,如果为true我们就重复做上面的判断
即判断BaseResponse中,T的类型是否为List,数组,Map还是对象?
然后在用对应的字段保存对应的类型名,取本地缓存的时候就可以用Gson按这些字段恢复正确的数据类型,但是这样强制的判断instanceof对于一个框架来说灵活性和扩展性会大打折扣,所以我后面写源码分析的时候会认真考虑下这个问题,可以的话我会Pull Request给Rxcache
- The end